
TLDR: I build an ML model to predict the perceived gender of a name in a given country. code is here.
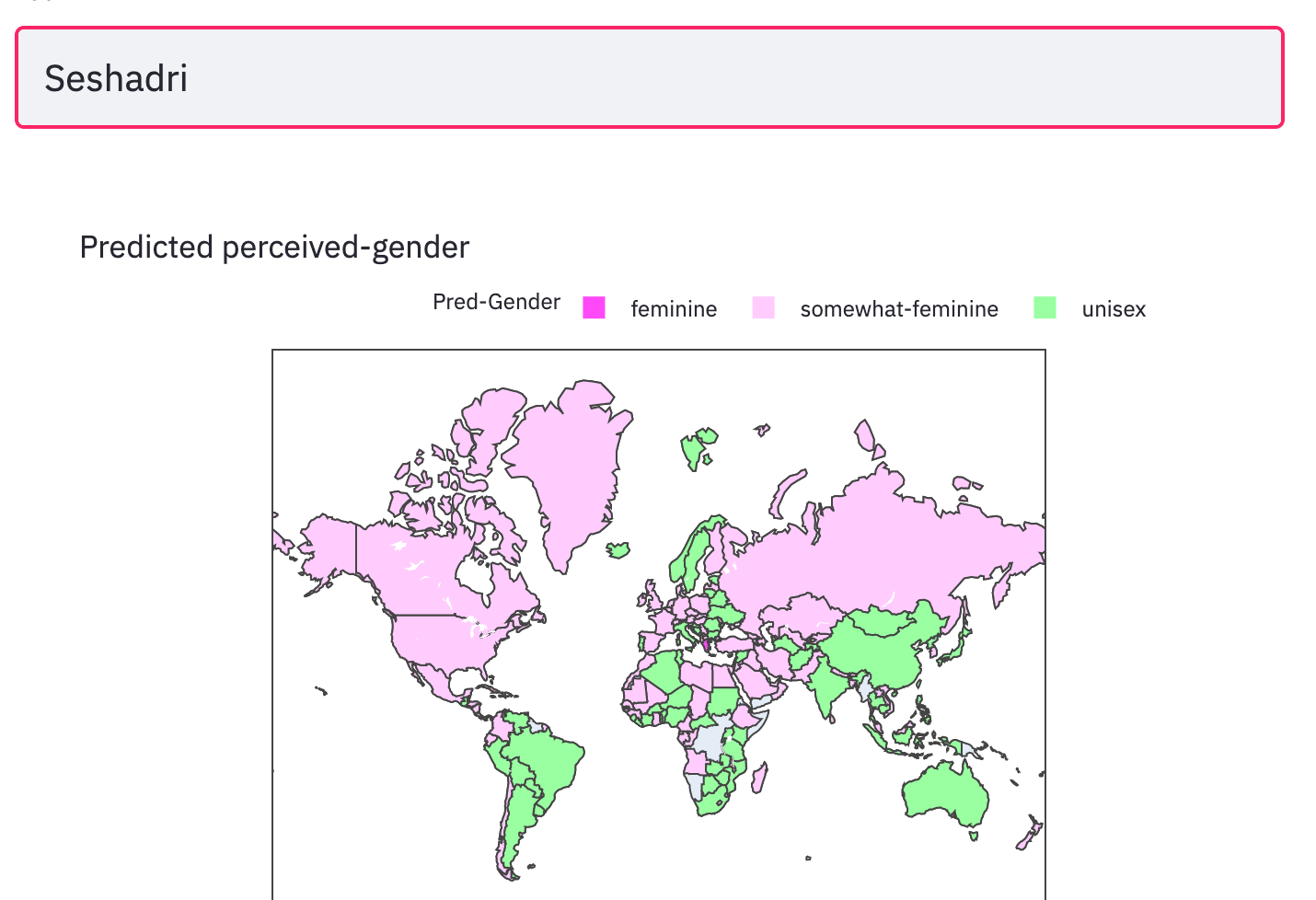
I was named Seshadri in honor of my late grandfather Seshadri Sampath. It is also one of the many names for the Hindu god Vishnu. In the south Indian state of Tamil Nadu where I'm from, my first name is understood to be masculine. However in other parts of the world, acquaintances express confusion at reconciling my gender with my name. Once an American phone operator asked that I put 'her'(Seshadri) on the phone upon hearing my male voice 🤦. Let us try to understand why this happens with machine learning. <drumroll>
hypothesis
Clearly the suffixed 'i' in my name is the cause for confusion because many names ending in 'i' tend to be female. I am interested in a person's experientially learned name to gender mapping. That would hopefully explain why Americans think my name sounds female. An individual's name to gender mapping is a product of their exposure to different cultures, individuals, texts etc. Their location in the world is likely the primary factor at play here.
dataset
I use the World Gender Name Dictionary (WGND) dataset which contains ~276k distinct <name, country> pairs; ~176k unique names from 172 countries. For each name we have gender found in different sources the data was collected from. For instance both male and female gender records with first-name "HARPER" are present. This dataset was originally created using name and gender information disclosed in patent applications worldwide (paper), to study gender and geographical disparities.
problem
My goal is to model a name's perceived gender for a given country. While gender identity itself is non-binary, we unfortunately only have access to name datasets with male and female pronouns. A name can be female, male or unisex (both) in the country of interest. I reduce this multi-class classification problem to a regression problem where the model predicts a maleness score. If all data sources unanimously indicate that the name was male, the score is 1. If they indicate that the name is female, the score is 0. If they are mixed, the score is the fraction of sources that say it is male. Unisex names would have a score close to .5
assumptions
The biggest leap of logic we make is to proxy the reported gender for a name as the perceived gender in the country. While they are not the same, it appears to me they are close enough. The dataset is hamstrung the lack of name frequency information. Without name weighting (typically a power-law distribution), a supervised model would not know that misclassifying "DAVID" is a costlier mistake compared to misclassifying "DRAVID" which is a rare name. Still, the dataset is viable; Popular names tend to be present in many countries, hence will have multiple records, so the frequency information isn't entirely lost.
preprocessing
The WGND paper noted stark gender disparities that varied by country. For instance, in Canada the number of female inventor names are higher than the males, while in India the female names are a third of the male names. To avoid learning incorrect priors on the imbalanced dataset, I undersample the majority gender class to select equal number of male and female records for each country. I also hid a few names when preparing the dataset. Seshadri and Sesh (my nickname) were held-out for obvious reasons. Cersei, Dobby, Daenerys and few other fictional names were also held-out to test how well the model generalizes.
max_name_length = max(map(len, names_df.name))
name_tokenizer = Tokenizer(num_words=None, char_level=True, oov_token='OOV')
name_tokenizer.fit_on_texts(names_df.name)
num_name_token_classes = len(name_tokenizer.word_index)+1
country_code_encoder = OneHotEncoder()
country_code_encoder.fit(names_df.country_code.to_numpy().reshape(-1, 1))
def get_names_matrix(names: pandas.Series):
return to_categorical(
pad_sequences(name_tokenizer.texts_to_sequences(names),
maxlen=max_name_length,
padding='post',
truncating='post'),
num_classes= num_name_token_classes)
def get_country_codes_matrix(codes: pandas.Series):
return country_code_encoder.transform(codes.to_numpy().reshape(-1, 1)).todense()
names_mat = get_names_matrix(names_df.name)
country_codes_mat = get_country_codes_matrix(names_df.country_code)
y_mat = names_df.maleness.to_numpy()model
I use an LSTM model to embed the sequence of name character tokens. The country code is one hot encoded and concatenated with the name embedding. This concatenated vector is passed through a single dense layer whose output is passed through a single unit sigmoid activation to predict the maleness score. We train it with early stopping, exiting when the validation mean-squared-error doesn't improve. The maleness score predictions on the held-out dataset are off by 0.26 on average, which is significantly better than the average score predictor.
inputs = [Input(shape=(max_name_length,num_name_token_classes), name="input_name_char_seq"),
Input(shape=(len(country_codes_unique),), name="input_country_code_ohe")]
lstm = LSTM(16, activation='relu', return_sequences=False)
name_embedding = lstm(inputs[0])
x = Concatenate(name="name_and_country_emb")([name_embedding, inputs[1]])
x = Dense(8,activation='relu')(x)
output = Dense(1, activation='sigmoid', name='maleness')(x)5573/5573 [==============================] - 54s 10ms/step
- loss: 0.1136 - mse: 0.1136 - mae: 0.2360
- val_loss: 0.1364 - val_mse: 0.1364 - val_mae: 0.2558visualization
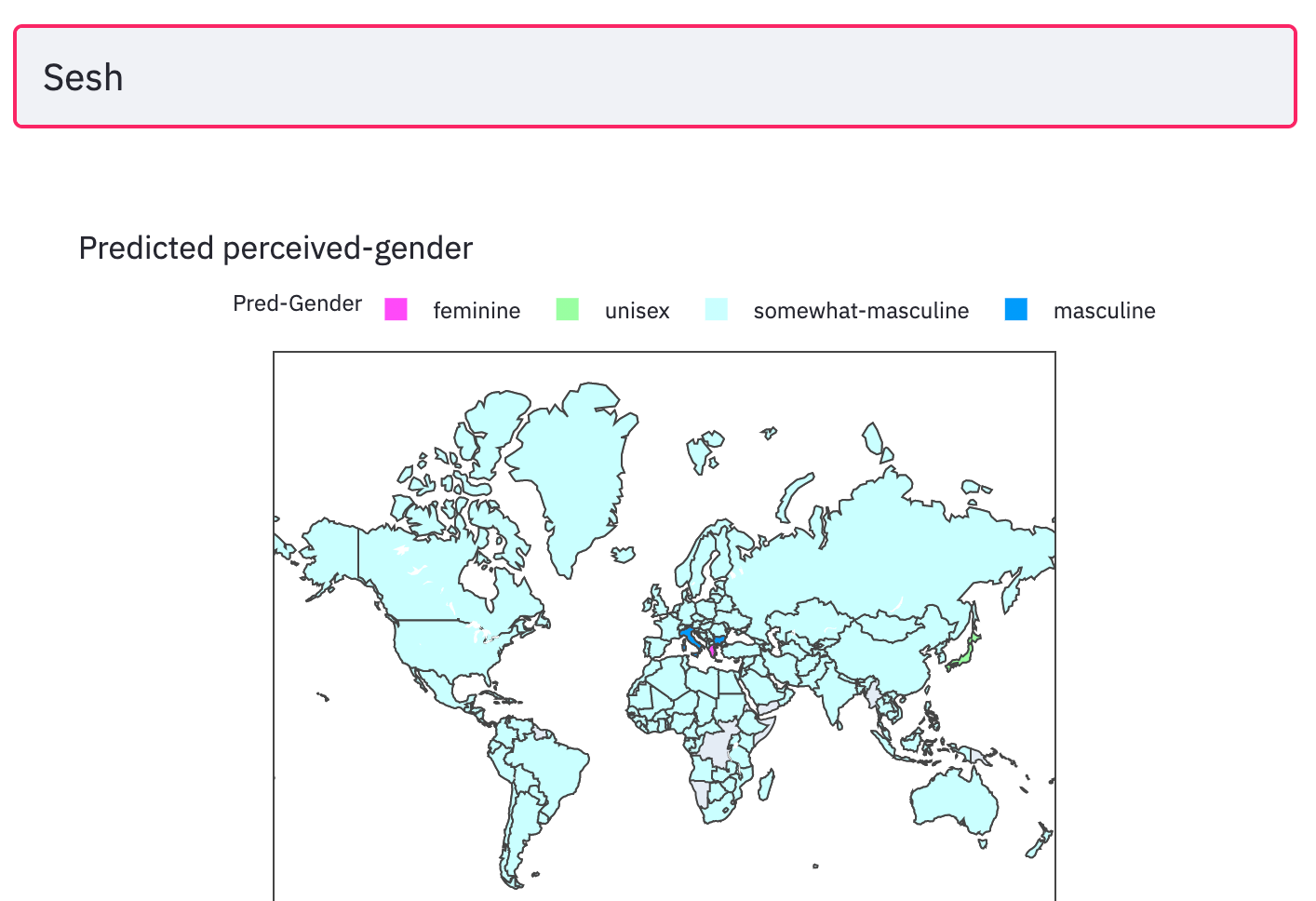
I made a Choropleth plot of the batch inference results predicting the maleness scores for every country in the dataset, for a given name input. The results below are for the holdout names.
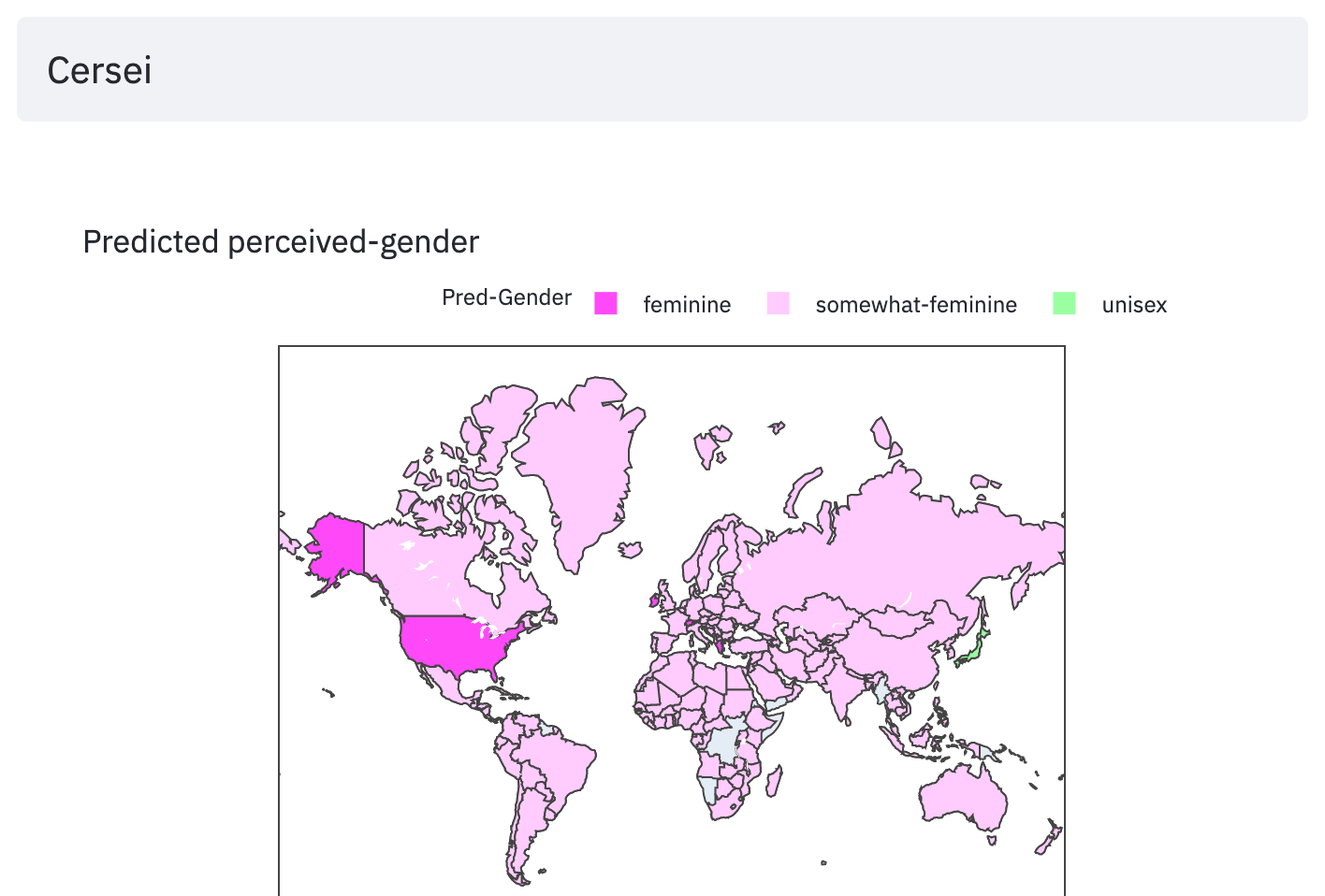
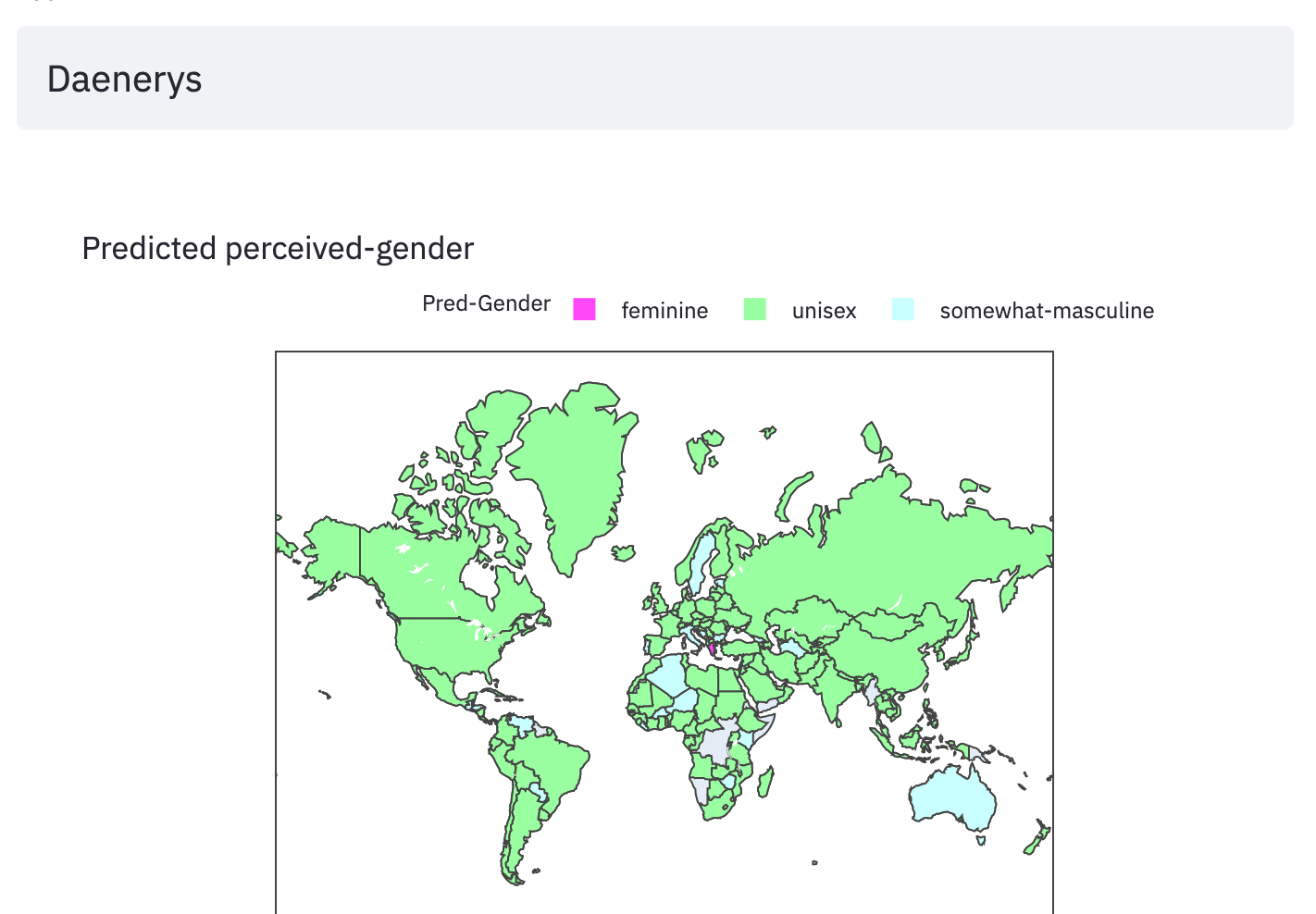
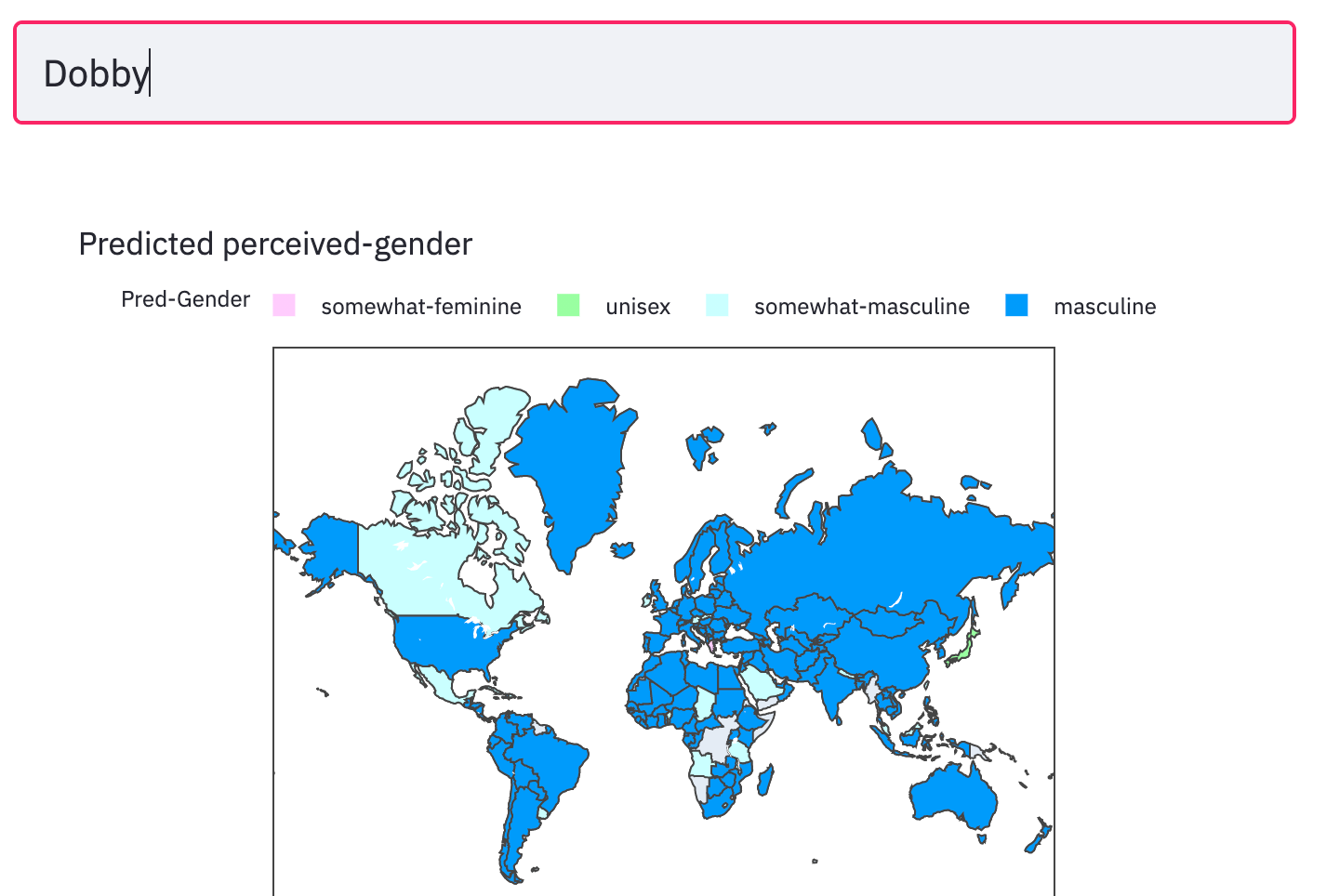
moment of truth
Aha! There it is. The model thinks my first-name sounds feminine to most of the western world; in India and few other places it is unisex. This prediction is largely in line with my experiential findings. Luckily the model predicts my nickname Sesh sounds masculine to most of the world.
observations
The model does well on made up names that sound male (ex: Halperbertson) or female (ex: Marienneesa). Starting with a name and altering its characters reveals which sounds the model is sensitive to (ex: Amir to Amira). It also appears to do a good job generalizing, predicting gender in countries where names were not seen. However there are plenty of spectacular mistakes. For instance 'Nikita' is predicted as female (apologies to Mr.Khrushchev), 'Gal Gaddot' as male. Some countries have sparse training data/coverage issues which comes through in the quality of its predictions.
The model does well at predicting gender for brand names. The predictions below make sense to me; my blind guesses for the same more or less match the model results. Interestingly studies indicate that feminine brand names are perceived by consumers as warmer and are better liked and frequently chosen. Before naming your next company do run it by the model!
thoughts
To deploy such a model for any practical application needs a whole lot more work. Name gender relationship is constantly evolving (ex: Kanye's daughter North West) and any model trained on a snapshot-in-time will have a finite shelf life. Pronoun scores for a name derived from global/local web-texts is a highly predictive signal that is worth adding. Features could also be extracted from online personas with those names. A potentially larger, current dataset could even be bootstrapped from Wikipedia. Such signals/datasets would need to be precomputed or created online using search-apis both of which would make the system more complicated.
In a world where in-person interactions are reducing and online interactions are quickly becoming the norm, the gender clues left by our name or user-name can trigger subconscious biases. Numerous papers have studied the effect of perceived gender and it's accompanied stereotyping on an individual's success in the real world - on visibility, on ratings, on trust. Maybe this should be of interest to us all.
Cheers,
Seshadri Sesh